How compiled computer languages are made? An Overview...
Glance over the process of compilation, linking and loading which makes it possible to run a binary code over a processor unit.
Writing an application or a program to show hello world on the terminal is cool in itself but the art of converting one piece of data(text code) into another( assembly or binary) which has a specific structure that enables it to run on a machine called the processor has a special mystery vibe to it. The process of conversion is called compilation. We shall also see how linking and loading works at a high level in the next article.
There is an alternate to compilation, called interpretation! But we are going to turn a blind eye towards that for now as it is similar in the initial stages to the compilation, only after the AST (Abstract Syntax Tree, coming later in the blog) is prepared, things go in different angles.
Compilation
Once you have a compiler, you can say that a language is created. A high level list of things one need to do in order to perform a compilation is as follows:
- Lexical Analysis(front-end): Tokenization of the input string, using regular expressions for it. Basically creating tokens out of the list of words presented in the code.
- Parsing(front-end): The stream of tokens is passed into a system which converts each sequence of tokens into a logical structure of a tree called an Abstract Syntax Tree(AST) which holds the meaning of the code.
- Abstract Syntax Tree: The AST logically holds the same code as the text file we started with and is then passed to the backend of the compilation process to be converted into another representation called as Assembly code.
- Intermediate Representation(back-end): Sometimes we need a specific back-end to work on our AST so we generate an intermediate representation of the AST which is then subjected to various optimization and code reduction and finally code generation.
- Code Generation(back-end): This is last step in the process of compilation. We generate machine code at the end after performing various compile time optimization like removing dead and unreachable code, minimization of code and registers assignment(we will talk about this more later).
There are a lot of data structures that the compiler creates for the linking and loading processes, for example symbol tables, which we are selectively choosing to avoid for this article.
Lexical Analysis or Tokenization
The process of creating a sequence of tokens for each word in the code is called Lexical Analysis. If the code contains the string
int i=10;
then 5 tokens are generated for this single line :
- TYPE_TOKEN that contains 'int' as its data.
- IDENTIFIER_TOKEN that contains the name of the identifier, i.
- OPERATOR_TOKEN that contains '=' as its data member.
- LITERAL_TOKEN that contains '10' as its data;
- SEMICOLUMN_TOKEN which is self sufficient as there is only one type of semicolumn.
In order to perform these operations Regular Expressions are used in the core. There are a plenty of tools which can help in creating a lexer for you instead of you writing one by hand. In the old days there were lex and flex available which are still used nowadays, but there are more modern solutions like ANTLR. Just define your tokens and it will generate a lexical analyzer for you.
Note: The spelling mistakes of sort are identified here.
Parsing
Once we have created a list of tokens we have to understand the meaning of the group of these tokens at a time. All the tokens are doing is keep data structured so that parser can easily make decisions regarding the grammar of the code. It is an important step as its result an AST is about to be generated.
We tell the parser generators like bison and ANTLR of what kind of tokens means what by specifying a context-free or Backus-Normal Form grammar for the language and then these systems generate a parser for that specific grammar.
Let me show you an example of a grammar used in shell terminals
commandline ::= list
| list ";"
| list "&"
list ::= conditional
| list ";" conditional
| list "&" conditional
conditional ::= pipeline
| conditional "&&" pipeline
| conditional "||" pipeline
pipeline ::= command
| pipeline "|" command
command ::= word
| redirection
| command word
| command redirection
redirection ::= redirectionop filename
redirectionop ::= "<" | ">" | "2>"Real languages also have grammars, e.g. read the complicated C++ grammar in BCNF form: here
There are multiple types of parsing techniques and algorithms like LALR(1), LL(1), LL(k), Operator Precedence. Basically all the parsers can be divided into Top-Down parsers and Bottom-Up parsers. Tools like Bison generate Bottom-Up parsers which are also called shift-reduce parsers.
No matter the type of the parser, end result is the same, an Abstract Syntax Tree(AST) logically holding all the pieces together.
Note: Syntactical mistakes are captured in this process
Abstract Syntax Tree
AST holds all the components of the language code in its core form only containing data that is crucial for its execution by the later stages.
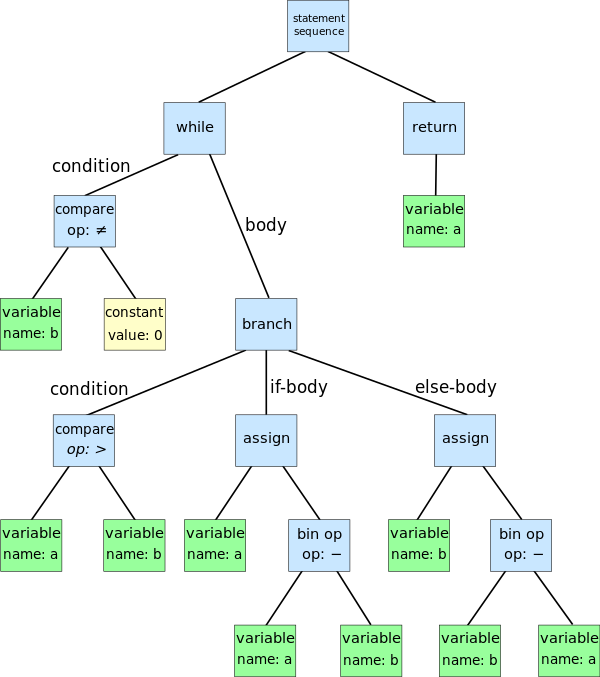
AST helps perform various optimizations over the code because it is not in text and there is logical ordering of things.
This is the point where the processes of compilation and interpretation starts to diverge. An interpreter is a program which takes in this AST and understands and executes these instructions in itself without ever having to convert it to the machine language, whereas, in compilation the AST is converted into a proper machine language code.
Intermediate Representation
So now that we have an AST we can use a tool called LLVM. It is one of the most complicated tools that I have ever seen. Basically it takes the AST and generates the (almost) optimized machine code. It is the technology behind Clang C/C++ compiler, Swift and Rust languages also use this as their compilation back-end.
int add(int a, int b) {
return a + b;
}
int main() {
return add(10, 20);
}
This above code in C is converted to LLVM IR below by executing the command: clang -emit-llvm -S add.c -o add.ll
define i32 @add(i32 %a, i32 %b) {
; <label>:0
%1 = add i32 %a, %b
ret i32 %1
}
define i32 @main() {
; <label>:0
%1 = call i32 @add(i32 10, i32 20)
ret i32 %1
}So the AST is then converted into as LLVM Intermediate Representation(IR) which is somewhere in middle of C and assembly language. This IR is then understood by the LLVM system. LLVM holds decades worth of optimization strategies which boosts up the code execution speed tremendously at the same time reducing the number of operations and code size!
Code Generation - Architecture Dependent
The real hardware processor needs to communicate with the RAM and the peripherals. It has some registers which can be used to hold data for an imminent need. So the code generation should be done in order for the maximal and most efficient use of these hardware features of the processor.
At this stage the LLVM system can generate the code by assigning actual hardware related components to the process. All the previous steps were independent of the real hardware unlike this process which is highly processor dependent!
LLVM, which is responsible for being the back-end for most of the common modern languages, needs to have information about all the possible architectures and it makes your code platform independent because if one writes a code generator by hand then it needs to address all the architecture so one would reinventing the wheel.
The generated code is called Object Code for that architecture.
Conclusion
Compiled code or Object file is generated at the end of last step, but this is far from being executed as we shall see in the next article that the object files need to be linked together and then loaded into the memory as particular locations to be able to run.